在Python中使用Pandas.DataFrame对Excel操作笔记一 |
您所在的位置:网站首页 › pandas excel数据处理 › 在Python中使用Pandas.DataFrame对Excel操作笔记一 |
在Python中使用Pandas.DataFrame对Excel操作笔记一
|
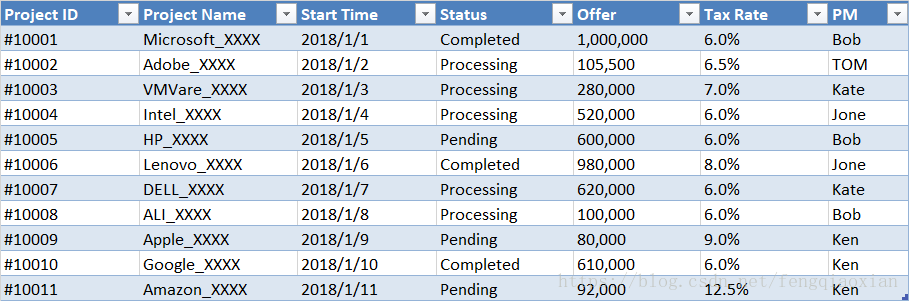
近期和朋友小A聊天的时候,总是听小A说工作越来越烦,有大量的Excel表格需要分析整理 ~~~,需要总结各种数据,做统计汇总之类,@#¥%%~~。像我等懒人,是不能容忍做大量重复性工作的。以懒人的观点来看,凡重复性的,必定有其规律啊,像太阳东升西落,像季节四季更替。只要有规律可循,就可以用工具来自动分析。能让机器做的事情,人就可以解放一下了嘛,就有更多的时间享受工作和生活了,吼吼吼 出于对小A的同情,我决定写一个工具,来自动解析这“大量”的Excel表格(详谈后才知道,其实小A说的大量,也就几个上千行的表格而已)。这里记录下一些Pandas对Excel的操作过程,供自己和码友们交流,共同提高、不断改进。 环境:Python3.6 + Pandas(0.22) 有一个1000行,28列的表格,包含了公司每个项目的各种信息(项目ID,名称,开始时间,状态,结束时间,报价,税率……)。这么多列,看了确实头晕??@_@??。这里我做了一个简单的表格,来说明一下Pandas是如何读取、筛选Excel的。
import pandas as pd excelFile = r'TEMP.xlsx' df = pd.DataFrame(pd.read_excel(excelFile)) print(df) 读取信息到DataFrame里面就这么简单,只需要提供一个excel的名称就好了,当然默认的Sheet名称是Sheet1。我们可以指定读取Sheet的名称的。且看 read_excel 的定义。 def read_excel(io, sheet_name=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None, usecols=None, parse_dates=False, date_parser=None, na_values=None, thousands=None, convert_float=True, converters=None, dtype=None, true_values=None, false_values=None, engine=None, squeeze=False, **kwds): 这里不做过多说明,详细参数说明官方网站 http://pandas.pydata.org/pandas-docs/version/0.22/api.html。 print(df) 读取到的信息如下,是不是很简单(向Pandas开发团队致敬): Project ID Project Name Start Time Status Offer Tax Rate PM 0 #10001 Microsoft_XXXX 2018-01-01 Completed 1000000 0.060 Bob 1 #10002 Adobe_XXXX 2018-01-02 Processing 105500 0.065 TOM 2 #10003 VMVare_XXXX 2018-01-03 Processing 280000 0.070 Kate 3 #10004 Intel_XXXX 2018-01-04 Processing 520000 0.060 Jone 4 #10005 HP_XXXX 2018-01-05 Pending 600000 0.060 Bob 5 #10006 Lenovo_XXXX 2018-01-06 Completed 980000 0.080 Jone 6 #10007 DELL_XXXX 2018-01-07 Processing 620000 0.060 Kate 7 #10008 ALI_XXXX 2018-01-08 Processing 100000 0.060 Bob 8 #10009 Apple_XXXX 2018-01-09 Pending 80000 0.090 Ken 9 #10010 Google_XXXX 2018-01-10 Completed 610000 0.060 Ken 10 #10011 Amazon_XXXX 2018-01-11 Pending 92000 0.125 Ken 需求一: 我们只想要 Project Name、Status、Offer、Tax Rate、PM 这几列的信息: import pandas as pd excelFile = r'TEMP.xlsx' df = pd.DataFrame(pd.read_excel(excelFile)) df1= df[['Project Name', 'Status', 'Offer', 'Tax Rate', 'PM']] print(df1)
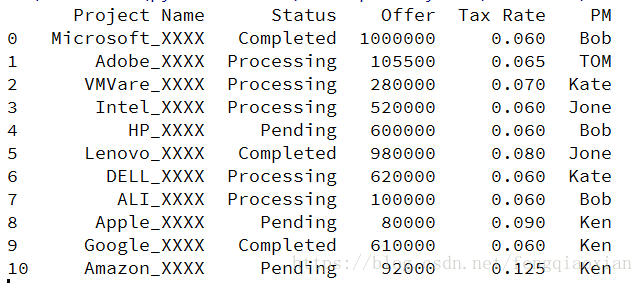
需求二: 我们只想要 统计 Bob 的项目
import pandas as pd excelFile = r'TEMP.xlsx' df = pd.DataFrame(pd.read_excel(excelFile)) df1 = df[['Project Name', 'Status', 'Offer', 'Tax Rate', 'PM']] df2 = df1.loc[df1['PM'] == 'Bob'] print(df2)
import pandas as pd excelFile = r'TEMP.xlsx' df = pd.DataFrame(pd.read_excel(excelFile)) df1 = df[['Project Name', 'Status', 'Offer', 'Tax Rate', 'PM']] df2 = df1.loc[df1['PM'] == 'Bob'].loc[df1['Status'] == 'Completed'] print(df2)
import pandas as pd excelFile = r'TEMP.xlsx' df = pd.DataFrame(pd.read_excel(excelFile)) df1 = df[['Project Name', 'Status', 'Offer', 'Tax Rate', 'PM']] df2 = df1.loc[df1['PM'] == 'Bob'].loc[df1['Status'] == 'Completed'] #获取PM列的值 pmList = df1[['PM']].values.T.tolist()[:][0] print(pmList) #排除重复值 pmList = list(set(pmList)) print(pmList) for pm in pmList: dfByPM = df1.loc[df1['PM'] == pm] print('\r\n') print(dfByPM) 结果如下:
~~~~~2018/05/29 更新 ~~~~~~~ 需求四:
来统计每位PM所有Offer列的总和。 import pandas as pd excelFile = r'TEMP.xlsx' df = pd.DataFrame(pd.read_excel(excelFile)) # 获取PM列的值 pmList = df[['PM']].values.T.tolist()[:][0] print(pmList) # 排除重复值 pmList = list(set(pmList)) print(pmList) sum_list = [['PM', 'Offer']] for pm in pmList: temp = [] dfByPM = df.loc[df['PM'] == pm] temp.append(pm) for col in dfByPM.columns: if col == 'Offer': sumValue = dfByPM[col].sum() #计数指定列的和 temp.append(sumValue) sum_list.append(temp) print(sum_list) 运行结果如下: [['PM', 'Offer'], ['Ken', 782000], ['Kate', 900000], ['Bob', 1700000], ['TOM', 105500], ['Jone', 1500000]] 需求五: 如何把这些信息写入到Excel里面呢?且往下看…… pandas.DataFrame.to_excel 这是一个特别惹人爱的函数,由dataframe对象直接调用,然后指定文件名、表名等各种参数。函数定义如下:
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)
更详细的说明可以看这里:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_excel.html#pandas.DataFrame.to_excel 思路:我们先把一个二维列表转换成dataframe对象,然后再调用这个pandas.DataFrame.to_excel函数 summaryDataFrame = pd.DataFrame(sum_list) summaryDataFrame.to_excel(filePath, encoding='utf-8', index=False, header=False)filePath, encoding='utf-8', index=False, header=False)运行后就会在filePath下面发现新生成的文件。 对excel的查询及再存储就简单记录到这里,后续说说修改Excel的样式及在现存excel里面添加内容 |
 。
。
 我们只想要 统计 Bob 的,Status为Completed的项目
我们只想要 统计 Bob 的,Status为Completed的项目 需求三: 来统计PM各自的项目信息。 分析:首先我们要知道都有哪些PM,这在表的PM列里面有。
需求三: 来统计PM各自的项目信息。 分析:首先我们要知道都有哪些PM,这在表的PM列里面有。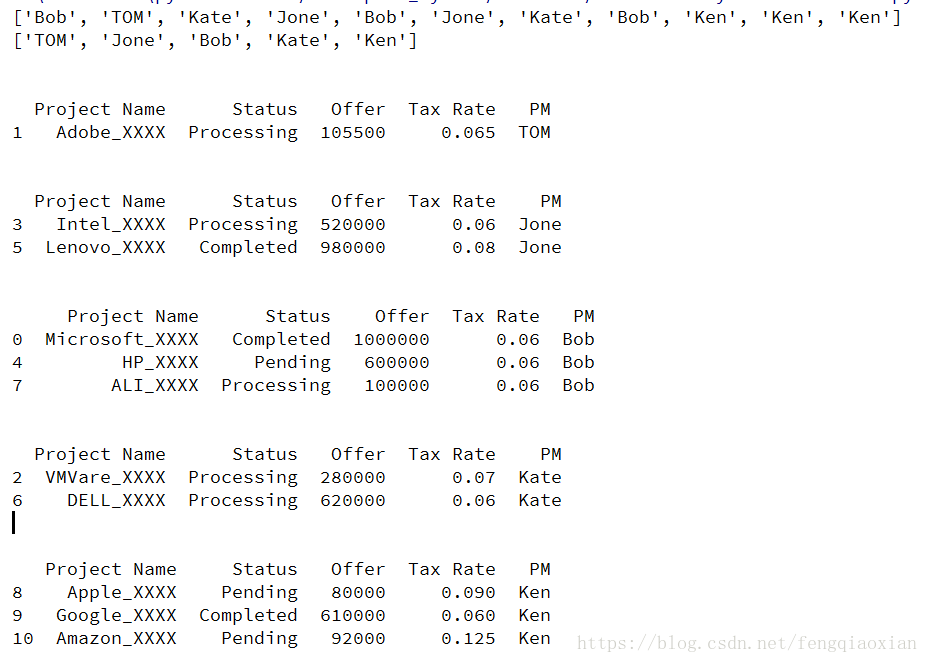 pandas 是不是很强大,我们只需要很少的代码,就可以读取和查询excel的几乎所有内容。
pandas 是不是很强大,我们只需要很少的代码,就可以读取和查询excel的几乎所有内容。
【本文地址】
今日新闻 |
推荐新闻 |